This AI Paper Introduces Optimal Covariance Matching for Efficient Diffusion Models



Probabilistic diffusion models have become essential for generating complex data structures such as images & videos. These models transform random noise into structured data, achieving high realism and utility across various domains. The model operates through two phases: a forward phase that gradually corrupts data with noise and a reverse phase that systematically reconstructs coherent data. Despite the promising results, these models often require numerous denoising steps and face inefficiencies in balancing sampling quality with computational speed, motivating researchers to seek ways to streamline these processes.
A major problem with existing diffusion models is the need for more efficient production of high-quality samples. This limitation primarily arises from the extensive number of steps required in the reverse process and the fixed or variably learned covariance settings, which don’t adequately optimize output quality relative to time and computational resources. Reducing covariance prediction errors could speed up the sampling process while maintaining output integrity. Addressing this, researchers seek to refine these covariance approximations for more efficient and accurate modeling.
Conventional approaches like Denoising Diffusion Probabilistic Models (DDPM) handle noise by applying predetermined noise schedules or learning covariance via variational lower bounds. Recently, state-of-the-art models have moved towards directly learning covariance to enhance output quality. However, these methods come with computational burdens, especially in high-dimensional applications where the data requires intensive calculations. Such limitations hinder the models’ practical application across domains needing high-resolution or complex data synthesis.
The research team from Imperial College London, University College London, and the University of Cambridge introduced an innovative technique called Optimal Covariance Matching (OCM). This method redefines the covariance estimation by directly deriving the diagonal covariance from the score function of the model, eliminating the need for data-driven approximations. By regressing the optimal covariance analytically, OCM reduces prediction errors and enhances sampling quality, helping to overcome limitations associated with fixed or variably learned covariance matrices. OCM represents a significant step forward by simplifying the covariance estimation process without compromising accuracy.
The OCM methodology offers a streamlined approach to estimating covariance by training a neural network to predict the diagonal Hessian, which allows for accurate covariance approximation with minimal computational demands. Traditional models often require the calculation of a Hessian matrix, which can be computationally exhaustive in high-dimensional applications, such as large image or video datasets. OCM bypasses these intensive calculations, reducing both storage requirements and computation time. Using a score-based function to approximate covariance improves prediction accuracy while keeping computational demands low, ensuring practical viability for high-dimensional applications. This score-based approach in OCM not only makes covariance predictions more accurate but also reduces the overall time required for the sampling process.

Performance tests demonstrate the significant improvements OCM brought in the quality and efficiency of generated samples. For instance, when tested on the CIFAR10 dataset, OCM achieved a Frechet Inception Distance (FID) score of 38.88 for five denoising steps, outperforming the traditional DDPM, which recorded an FID score of 58.28. With ten denoising steps, the OCM approach further improved, achieving a score of 21.60 compared to DDPM’s 34.76. These results indicate that OCM enhances sample quality and reduces the computational load by requiring fewer steps to achieve comparable or better results. The research also revealed that OCM’s likelihood evaluation improved significantly. Using fewer than 20 steps, OCM achieved a negative log-likelihood (NLL) of 4.43, surpassing conventional DDPMs, which typically require 20 steps or more to reach an NLL of 6.06. This increased efficiency suggests that OCM’s score-based covariance estimation could be an effective alternative in both Markovian and non-Markovian diffusion models, reducing time and computational resources without compromising quality.
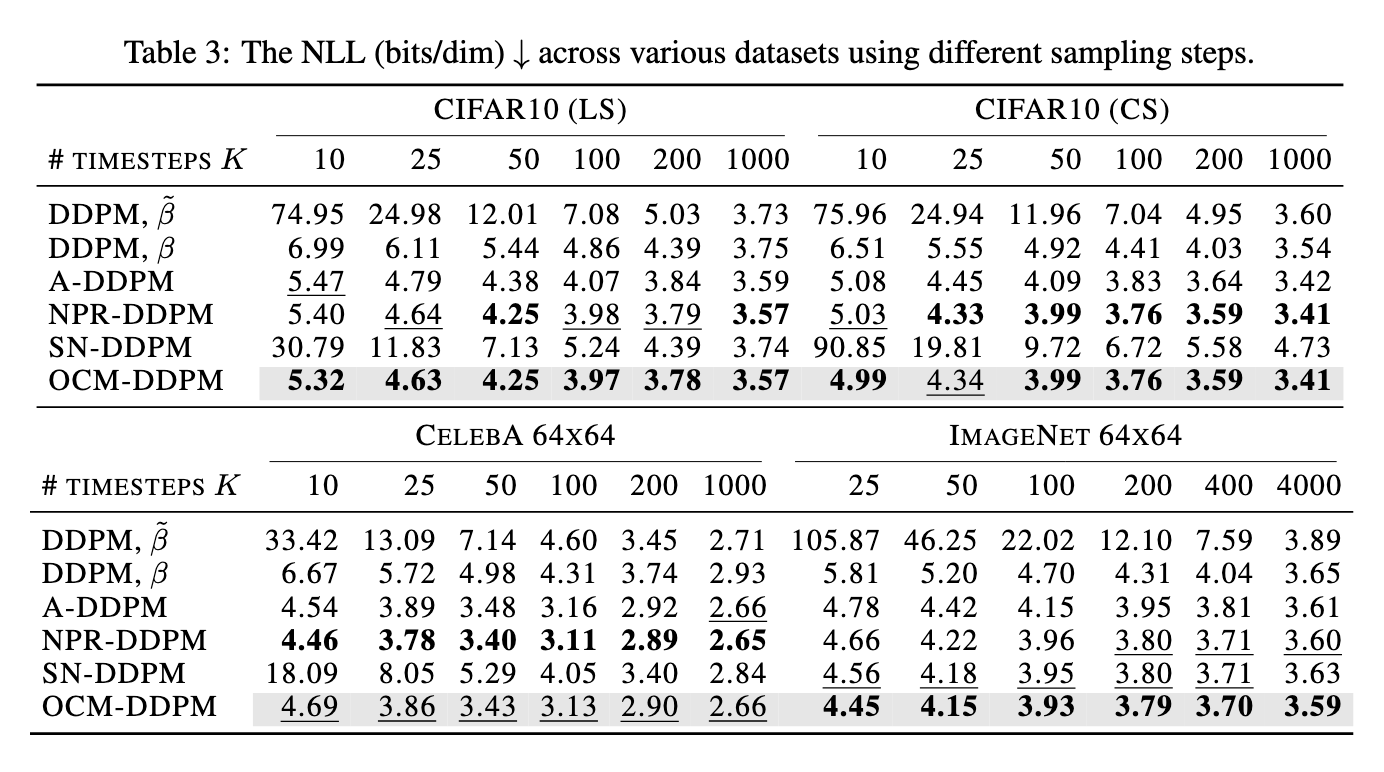
This research highlights an innovative method of optimizing covariance estimation to deliver high-quality data generation with reduced steps and enhanced efficiency. By leveraging the score-based approach in OCM, the research team provides a balanced solution to the challenges in diffusion modeling, merging computational efficiency with high output quality. This advancement may significantly impact applications where rapid, high-quality data generation is essential.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.