TensorOpera AI Releases Fox-1: A Series of Small Language Models (SLMs) that Includes Fox-1-1.6B and Fox-1-1.6B-Instruct-v0.1


Recent advancements in large language models (LLMs) have demonstrated significant capabilities in a wide range of applications, from solving mathematical problems to answering medical questions. However, these models are becoming increasingly impractical due to their vast size and the immense computational resources required to train and deploy them. LLMs, like those developed by OpenAI or Google, often contain hundreds of billions of parameters, necessitating massive datasets and high training costs. This, in turn, results in financial and environmental burdens that make these models inaccessible to many researchers and organizations. The increasing scale also raises concerns about efficiency, latency, and the ability to deploy these models effectively in real-world applications where computational resources might be limited.
TensorOpera AI Releases Fox-1: A Series of Small Language Models (SLMs)
In response to these challenges, TensorOpera AI has released Fox-1, a series of Small Language Models (SLMs) that aim to provide LLM-like capabilities with significantly reduced resource requirements. Fox-1 includes two main variants: Fox-1-1.6B and Fox-1-1.6B-Instruct-v0.1, which have been designed to offer robust language processing capabilities while remaining highly efficient and accessible. These models have been pre-trained on 3 trillion tokens of web-scraped data and fine-tuned with 5 billion tokens for instruction-following tasks and multi-turn conversations. By making these models available under the Apache 2.0 license, TensorOpera AI seeks to promote open access to powerful language models and democratize AI development.
Technical Details
Fox-1 employs several technical innovations that make it stand out among other SLMs. One notable feature is its three-stage data curriculum, which ensures a gradual progression in training from a general to a highly specialized context. During pre-training, the data was organized into three distinct stages, using 2K-8K sequence lengths, allowing Fox-1 to effectively learn both short and long dependencies in text. The model architecture is a deeper variant of the decoder-only transformer, featuring 32 layers, which is significantly deeper compared to its peers, such as Gemma-2B and StableLM-2-1.6B.
In addition to the deeper architecture, Fox-1 uses Grouped Query Attention (GQA), which optimizes memory usage and improves both training and inference speeds. The expanded vocabulary size of 256,000 tokens further enhances the model’s ability to understand and generate text with reduced tokenization ambiguity. By sharing input and output embeddings, Fox-1 also reduces the total number of parameters, resulting in a more compact and efficient model. Together, these innovations enable Fox-1 to achieve state-of-the-art performance in language tasks without the computational overhead typically associated with LLMs.
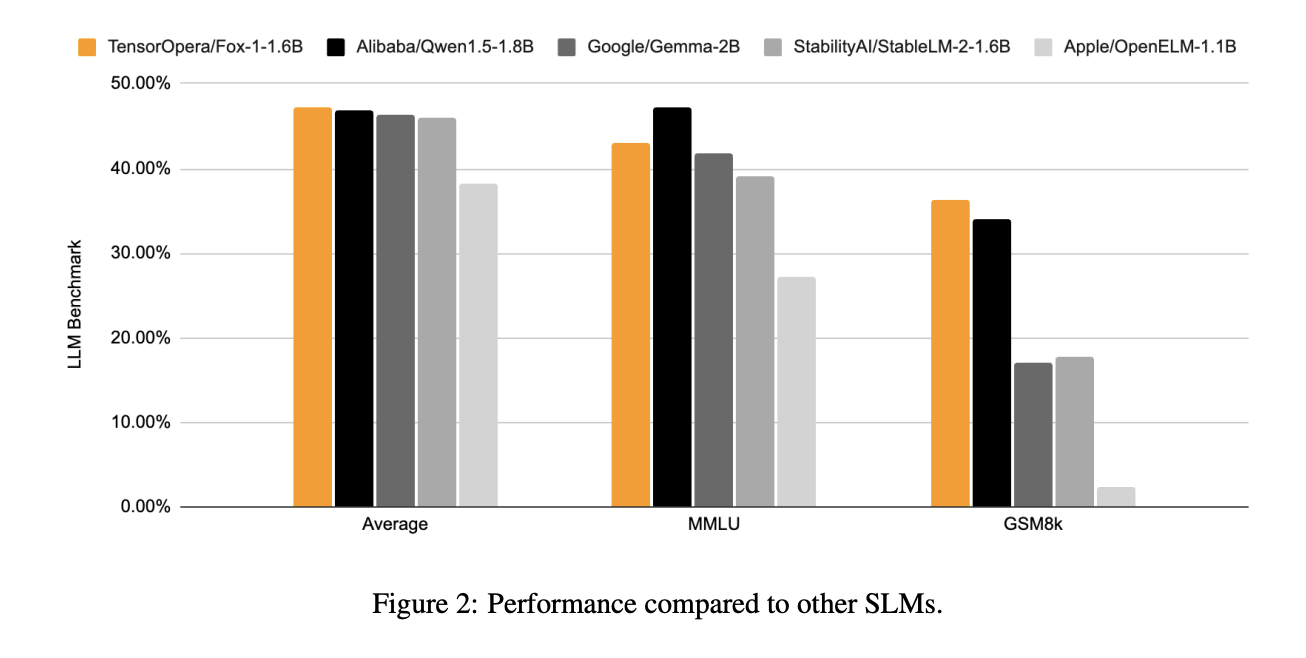
Performance Results
The release of Fox-1 is particularly important for several reasons. Firstly, it addresses the core issue of accessibility in AI. By providing a model that is both efficient and capable, TensorOpera AI is making advanced natural language understanding and generation available to a broader audience, including researchers and developers who may not have access to the computational infrastructure required for larger LLMs. Fox-1 has been benchmarked against leading SLMs like StableLM-2-1.6B, Gemma-2B, and Qwen1.5-1.8B, and has consistently performed on par or better in various standard benchmarks, such as ARC Challenge, MMLU, and GSM8k.

In terms of specific results, Fox-1 achieved 36.39% accuracy on the GSM8k benchmark, outperforming all compared models, including Gemma-2B, which is twice its size. It also demonstrated superior performance on the MMLU benchmark despite its smaller size. The inference efficiency of Fox-1 was measured using vLLM on NVIDIA H100 GPUs, where it achieved over 200 tokens per second, matching the throughput of larger models like Qwen1.5-1.8B while using less GPU memory. This efficiency makes Fox-1 a compelling choice for applications requiring high performance but constrained by hardware limitations.
Conclusion
The Fox-1 series by TensorOpera AI marks a significant step forward in the development of small yet powerful language models. By combining an efficient architecture, advanced attention mechanisms, and a thoughtful training strategy, Fox-1 delivers impressive performance comparable to much larger models. With its open-source release, Fox-1 is poised to become a valuable tool for researchers, developers, and organizations looking to leverage advanced language capabilities without the prohibitive costs associated with large language models. The Fox-1-1.6B and Fox-1-1.6B-Instruct-v0.1 models illustrate that it is possible to achieve high-quality language understanding and generation with a more efficient, streamlined approach.
Check out the Paper, Base Model, and Chat Model. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live LinkedIn event] ‘One Platform, Multimodal Possibilities,’ where Encord CEO Eric Landau and Head of Product Engineering, Justin Sharps will talk how they are reinventing data development process to help teams build game-changing multimodal AI models, fast‘
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
