Optimizing Long-Context Processing with Role-RL: A Reinforcement Learning Framework for Efficient Large Language Model Deployment


Training Large Language Models (LLMs) that can handle long-context processing is still a difficult task because of data sparsity constraints, implementation complexity, and training efficiency. Working with documents of infinite duration, which are typical in contemporary media formats like automated news updates, live-stream e-commerce platforms, and viral short-form movies, makes these problems very clear. Online Long-context Processing (OLP) is a new paradigm that is used to overcome this.
The OLP paradigm is specifically made to handle and process massive amounts of data in real-time, arranging and evaluating various media streams as they come in. OLP can assist in segmenting and categorizing streaming transcripts into relevant areas, such as product descriptions, pricing talks, or customer interactions, in live e-commerce. It can assist in organizing a constant stream of news data into groups such as facts, views, and projections in automated news reporting, which enhances the information’s accuracy and user-friendliness.
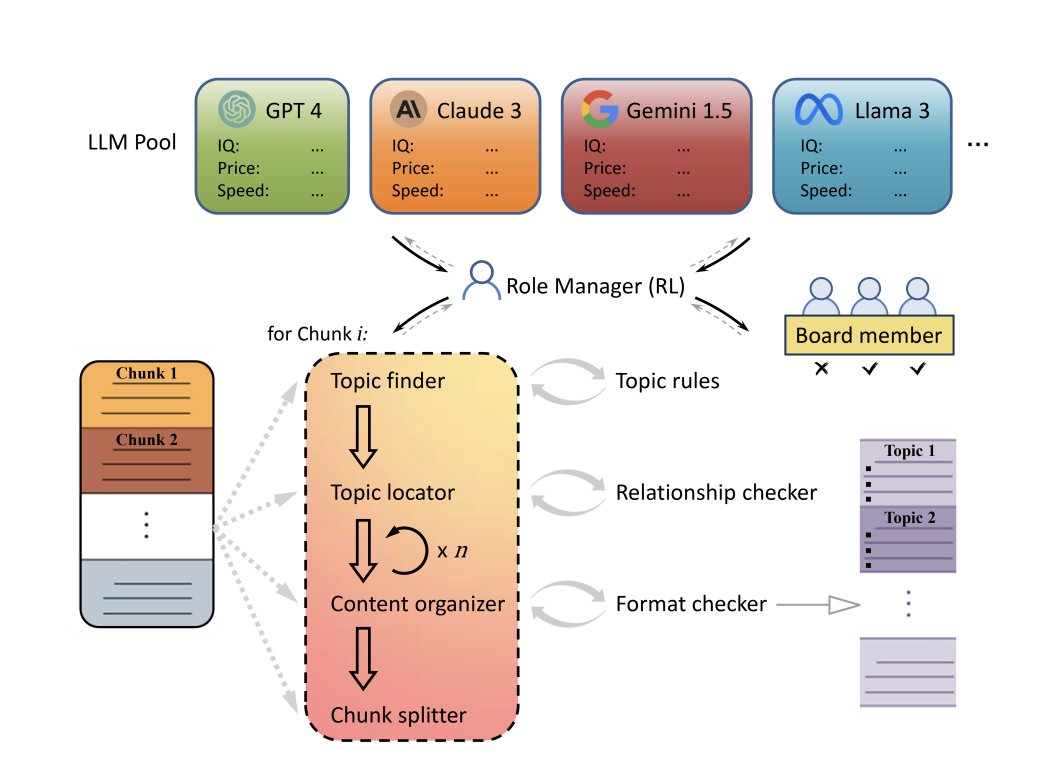
However, trying to choose the best available LLM from an ever-increasing pool of models presents another difficulty. It is challenging to identify a model that performs well in all of these areas because each one differs in terms of cost, response time, and performance. In response to this problem, a framework known as Role Reinforcement Learning (Role-RL) has been introduced in a recent research paper from South China Normal University, Toronto University and Zhejiang University. Role-RL uses real-time performance data to automate the deployment of various LLMs in the OLP pipeline according to their ideal roles.
Each LLM is assessed by Role-RL based on important performance metrics such as speed, accuracy, and cost-effectiveness. Role-RL maximizes the system’s overall efficiency by dynamically assigning each LLM to the tasks for which they are most suitable based on these evaluations. With this method, resources can be used more strategically, guaranteeing that high-performing LLMs take on the most important jobs and that more economical models are used for simpler procedures.
Extensive studies on the OLP-MINI dataset have revealed that the combined OLP and Role-RL framework yielded notable benefits. With an average recall rate of 93.2%, it achieved an OLP benchmark, demonstrating the system’s ability to reliably and frequently retrieve pertinent information. This framework was also responsible for a 79.4% cost reduction for LLM deployment, demonstrating its economic viability in addition to its efficiency.
The team has summarized their primary contributions as follows.
- The Role Reinforcement Learning (Role-RL) framework, has been introduced, which is intended to strategically place different LLMs in the roles that best fit them according to how well they perform in real-time on certain tasks. This guarantees that LLMs are deployed as efficiently and accurately as possible.
- To manage long-context jobs, the team has suggested Online Long-context Processing (OLP) pipeline. The pipeline processes and organises data from long documents or media streams in a successful manner. OLP-MINI dataset has also been presented for validation and testing.
- The benchmark average recall rate of 93.2% has been attained using the Role-RL framework in conjunction with the OLP pipeline. The framework also reduces LLM expenses by 79.4%. In addition, the recall rate is increased by 53.6 percentage points using the OLP pipeline as opposed to non-OLP procedures.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
