Model Kinship: The Degree of Similarity or Relatedness between LLMs, Analogous to Biological Evolution
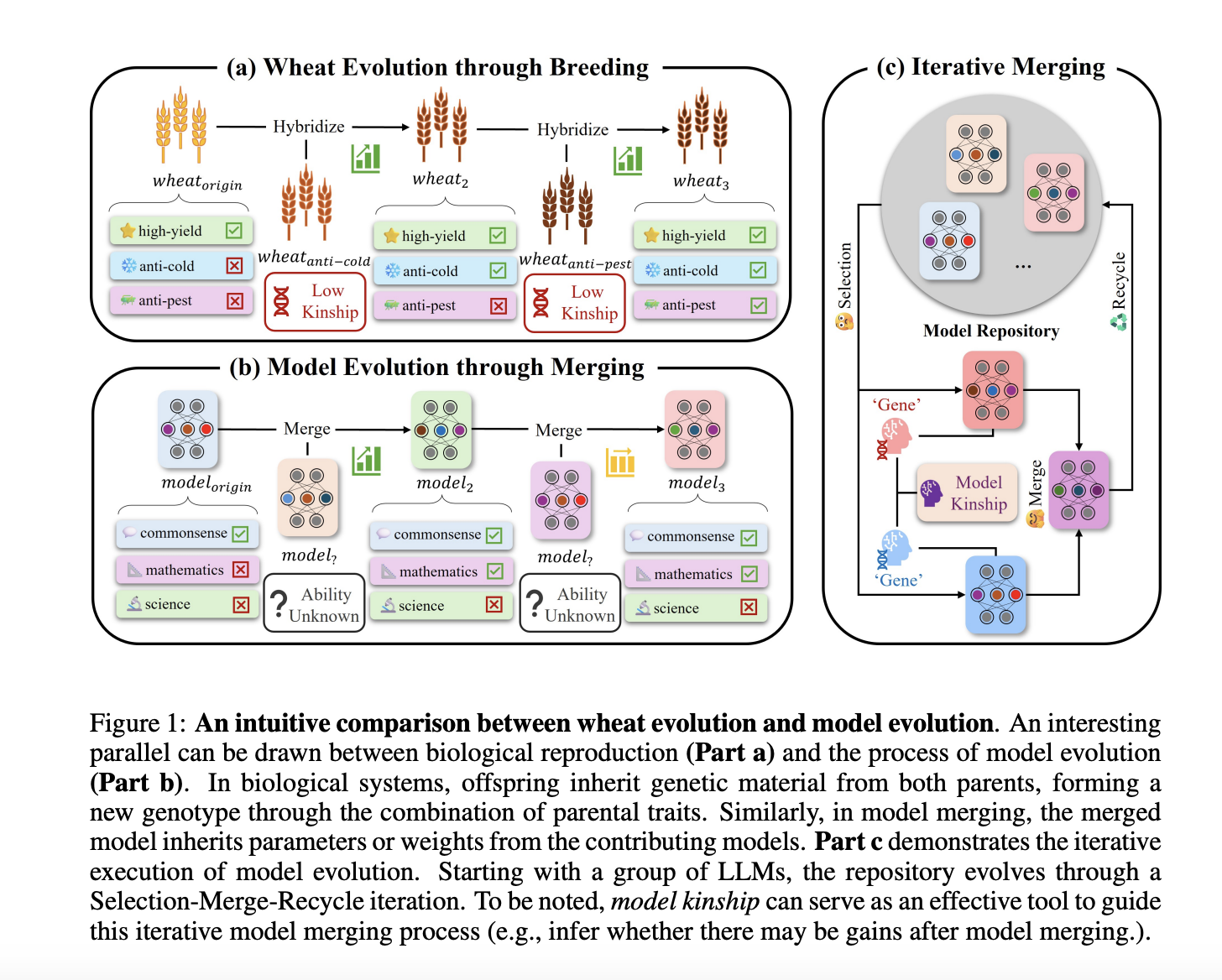


Large Language Models (LLMs) have gained significant traction in recent years, with fine-tuning pre-trained models for specific tasks becoming a common practice. However, this approach needs help in resource efficiency when deploying separate models for each task. The growing demand for multitask learning solutions has led researchers to explore model merging as a viable alternative. This technique integrates multiple expert models to achieve multitask objectives, offering a promising path for LLM evolution. Despite advancements in model merging toolkits and the development of more powerful LLMs through iterative merging, the process largely relies on trial and error and human expertise. As merging iterations progress, achieving further generalization gains becomes increasingly challenging, highlighting the need for a deeper understanding of the underlying mechanisms driving these advancements.
Researchers have explored various approaches to address the challenges of model merging and multitask learning in LLMs. Weight averaging, originating from Utans’ work in 1996, has been widely applied in deep neural networks for combining checkpoints, utilizing task-specific information, and parallel training of LLMs. The discovery of Linear Mode Connectivity (LMC) expanded the use of weight averaging in fusing fine-tuned models. Further studies have explored optimizable weights for merging, such as FisherMerging, RegMean, AdaMerging, and MaTS.
Task vectors and parameter interference reduction techniques like TIES and DARE have been developed to enhance multitask learning and prevent conflicts during merging. Model Breadcrumbs demonstrated the benefits of removing outlier parameters to reduce noise. For merging models with different initializations, methods exploiting neural network permutation symmetry and alignment techniques have been proposed.
Recent work has focused on “model evolution,” with approaches like CoLD Fusion for iterative fusion, automated merging tools on platforms like Hugging Face, and Evolutionary Model Merge employing evolutionary techniques to optimize model combinations. These advancements aim to uncover hidden patterns in the merging process that human intuition alone might miss.
Researchers from Zhejiang University and the National University of Singapore, NUS-NCS Joint Lab, introduce model kinship, drawing inspiration from evolutionary biology, to estimate the relatedness between LLMs during iterative model merging. This metric offers valuable insights to enhance merging strategies and enables comprehensive analysis of the merging process from multiple perspectives. The study reveals a strong correlation between multitask capability improvements and model kinship, which can guide the selection of candidate models for merging.
The research identifies two distinct stages in the model merging process: a learning stage with significant performance improvements and a saturation stage where improvements diminish. This observation suggests the presence of optimization challenges, such as local optima traps. To mitigate these issues, the researchers propose a robust strategy called Top-k Greedy Merging with Model Kinship.
The paper’s key contributions include the introduction of model kinship as a tool for assessing LLM relatedness, a comprehensive empirical analysis of model evolution through iterative merging, and practical model merging strategies utilizing model kinship. These advancements aim to improve the efficiency and effectiveness of model evolution, potentially revolutionizing auto-merging research in the field of LLMs.
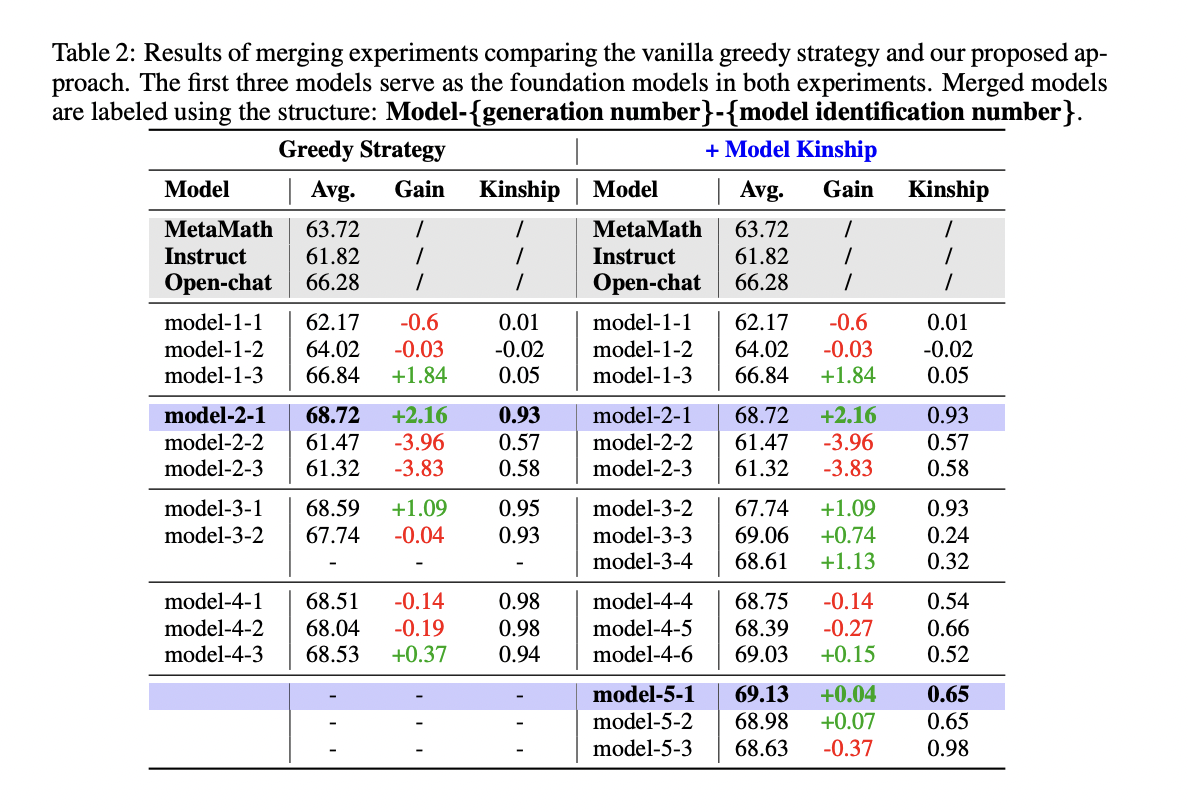
The researchers conducted two iterative model merging experiments using SLERP (Spherical Linear Interpolation) and the Mergekit toolkit. They compared two strategies: Top-k Greedy Merging and Top-k Greedy Merging with Model Kinship. The latter introduced an additional exploration step based on model kinship to discover potentially better solutions.
Results showed that both strategies achieved multi-task goals, but the vanilla greedy strategy stopped improving after Generation 2, stabilizing at an average task performance of 68.72. In contrast, the kinship-based method continued to improve, reaching 69.13 by Generation 5, effectively escaping local optima.
Analysis of weight changes revealed that merging models with low kinship introduced unique variations into the weight space, helping to escape local optima. This was evident in the significant weight changes observed when merging with exploration models.
The researchers also found that model kinship could serve as an effective early-stopping criterion. When model kinship between top-performing models exceeded 0.9, it indicated convergence. Implementing this as a stopping condition improved time efficiency by approximately 30% with minimal or no performance reduction.
This research introduces model kinship to guide the merging of Large Language Models, providing insights into the model evolution process. The proposed Top-k Greedy Merging with Model Kinship strategy demonstrates effectiveness in escaping local optima traps and enabling further improvements. Model kinship also serves as an early stopping criterion, reducing computational waste. Drawing parallels to biological hybridization, this work explores autonomous model evolution through merging. As language models continue to advance, these findings offer valuable insights into optimizing their development and performance, paving the way for more efficient and effective LLM evolution strategies.
Check out the Papers. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
