HuggingFace Researchers Introduce Docmatix: A Dataset For Document Visual Question Answering Containing 2.4 Million Pictures And 9.5 Million Q/A Pairs


Document Visual Question Answering (DocVQA) is a branch of visual question answering that focuses on answering queries about the contents of documents. These documents can take several forms, including scanned photographs, PDFs, and digital documents with text and visual features. However, there are few datasets for DocVQA because collecting and annotating the data is complicated. It requires understanding the context, structure, and layout of various document formats, which requires much manual effort. Due to the sensitive nature of the information contained within, many documents are inaccessible or have privacy concerns that make sharing or using them difficult. Domain-specific differences and the absence of document-structure uniformity further complicate the development of an exhaustive dataset. Factors contributing to the complexity of multi-modal fusion and the accuracy of optical character recognition also play a role.
Despite these challenges, the urgent need for more DocVQA datasets is underscored. These datasets are crucial for enhancing model performance, as they enable more thorough benchmarking and enhance model training for higher generalizability. By automating document-related processes across sectors and making documents more accessible through summary generation and query responding, updated DocVQA models could significantly impact document accessibility.
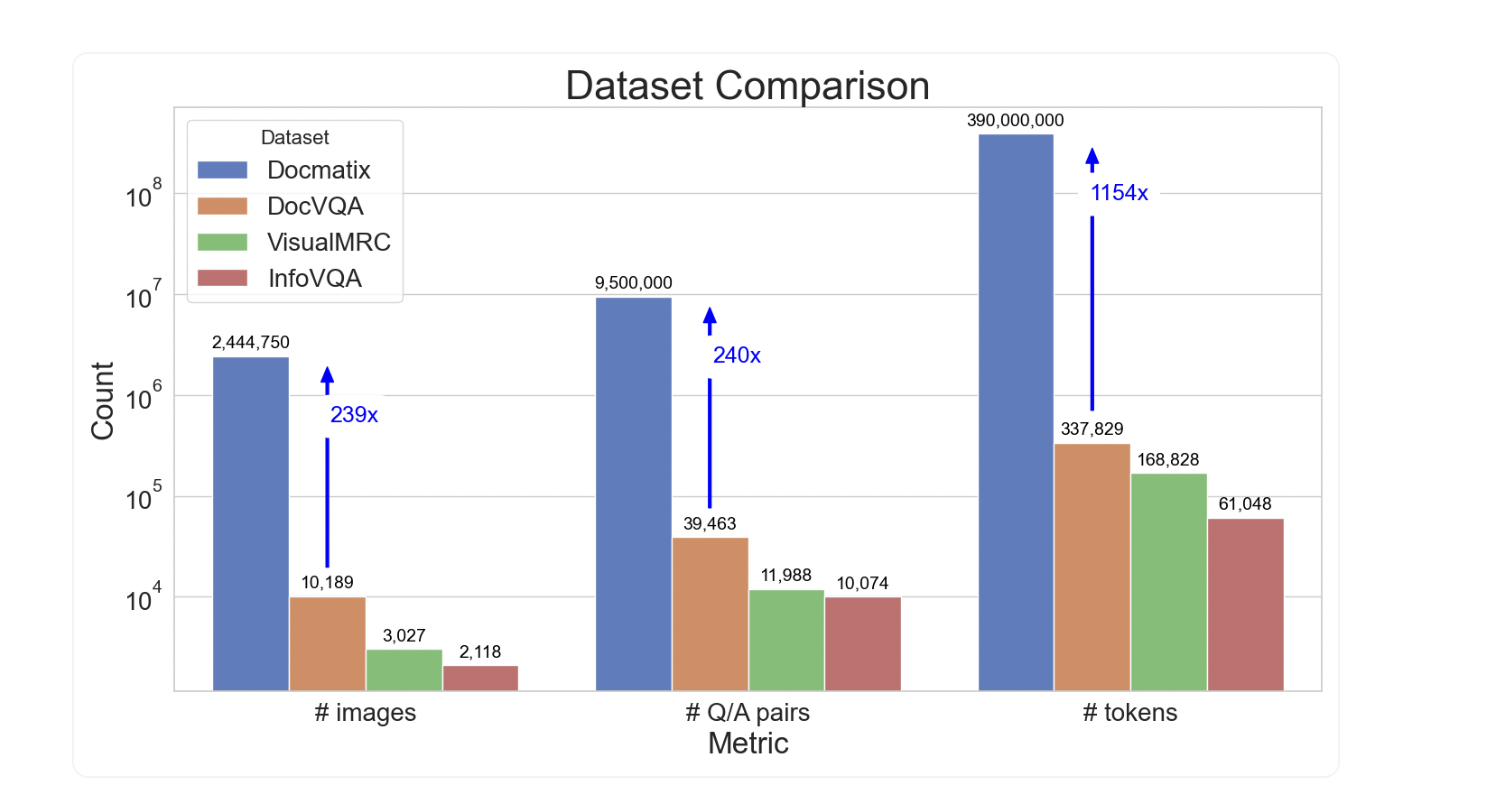
To fine-tune Vision-Language Models (VLMs), and Idefics2 in particular, researchers from HuggingFace initially built The Cauldron, a massive collection of fifty datasets. As a result of these efforts, the team discovered a severe shortage of high-quality datasets for Document Visual Question Answering (DocVQA). With 10,000 photos and 39,000 question-answer (Q/A) pairings, DocVQA was the main dataset used for Idefics2. There still needs to be a significant performance disparity between open-source and closed-source models, even after fine-tuning this and other datasets.
Their new study introduces Docmatix, a monumental DocVQA dataset containing 2.4 million pictures and 9.5 million Q/A pairs extracted from 1.3 million PDF documents. This scale, which has increased by 240 times compared to earlier datasets, showcases the potential impact of Docmatix.
The PDFA collection, which includes over two million PDFs, is the source of Docmatix. The researchers used a Phi-3-small model to create Q/A pairs using the PDFA transcriptions. To make sure the dataset was good, 15% of the Q/A pairings were removed that were found to be hallucinations during the creation filter. This was accomplished by eliminating responses that included the word “unanswerable” using regular expressions that detect code. There is a row in the dataset for every PDF. After processing the PDFs, the team saved 150 dpi photographs to the Hugging Face Hub. Now, anyone may access them with ease.
Users can place their full trust in Docmatix, as all PDFs can be traced back to the original PDFA dataset. Despite the resource-intensive process of converting several PDFs to photos, the researchers have uploaded the processed images for user convenience.
After processing the initial small dataset batch, the researchers ran multiple ablation experiments to fine-tune the prompts. They were aiming for approximately four question-and-answer pairs per page. A few pairs lack detail, whereas excess pairs indicate high overlap. Furthermore, they strived for responses resembling human speech, meaning they were neither lengthy nor brief. To avoid duplicating efforts, the questions were diverse. Surprisingly, there were few instances of question repetition when the Phi-3 model was instructed to inquire about certain details in the text (for example, “What are the titles of John Doe?”).
The team used the Florence-2 model to undertake ablation trials to assess Docmatix’s performance. To facilitate comparability, they trained a pair of versions of the model. The DocVQA dataset was used to train the initial version over multiple epochs. To ensure the model produced the right format for DocVQA evaluation, the second version was trained for one epoch on Docmatix (20% of the images and 4% of the Q/A pairs) and then for one epoch on DocVQA. The findings are noteworthy: a relative improvement of about 20% was produced by training on this tiny subset of Docmatix. Although much bigger, the 0.7B Florence-2 model only did 5% worse than the 8B Idefics2 model trained on various datasets.
The team hopes their work reduces the disparity between proprietary and open-sourced VLMs. To train a brand new, fantastic DocVQA model, they urge the open-source community to use Docmatix.
Check out the Dataset and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Find Upcoming AI Webinars here
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.

