ChunkRAG: An AI Framework to Enhance RAG Systems by Evaluating and Filtering Retrieved Information at the Chunk Level


Retrieval-augmented generation (RAG) systems, a key area of research in artificial intelligence, aim to enhance large language models (LLMs) by incorporating external sources of information for generating responses. This approach is particularly valuable in fields requiring accurate, fact-based answers, such as question-answering or information retrieval tasks. Yet, these systems often encounter substantial challenges in filtering irrelevant data during retrieval, leading to inaccuracies and “hallucinations” when the model generates information not based on reliable sources. Due to these limitations, the focus has shifted towards improving relevance and factual accuracy in RAG systems, making them suitable for complex, precision-driven applications.
The main challenge for RAG systems stems from retrieving only the most relevant information while discarding unnecessary or loosely related data. Traditional methods retrieve large sections of documents, assuming that pertinent information is contained within these lengthy excerpts. However, this approach often results in the generation of responses that include irrelevant information, affecting accuracy. Addressing this issue has become essential as these models are increasingly deployed in areas where factual precision is crucial. For instance, fact-checking and multi-hop reasoning, where responses depend on multiple, interconnected pieces of information, require a method that not only retrieves data but also filters it at a granular level.
Traditional RAG systems rely on document-level retrieval, reranking, and query rewriting to improve response accuracy. While these techniques aim to enhance retrieval relevance, they overlook the need for more detailed filtering at the chunk level, allowing extraneous information to slip into generated responses. Advanced approaches like Corrective RAG (CRAG) and Self-RAG attempt to refine responses by correcting errors post-retrieval or incorporating self-reflection mechanisms. However, these solutions still operate at the document level and need more precision to eliminate irrelevant details on a more granular scale, limiting their efficacy in applications demanding high levels of accuracy.
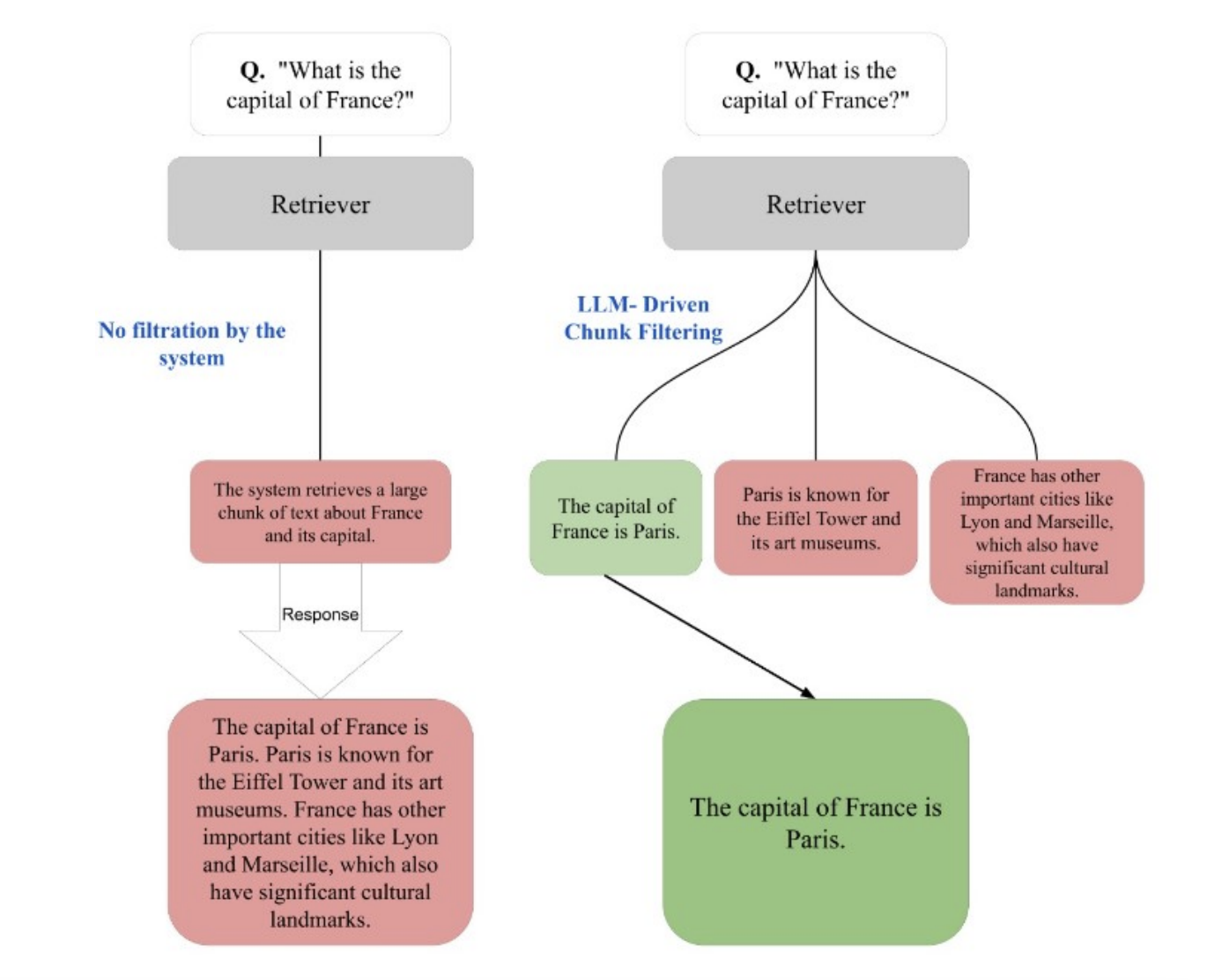
Researchers from Algoverse AI Research introduced ChunkRAG, a novel RAG approach that filters retrieved data at the chunk level. This approach shifts from traditional document-based methods by focusing on smaller, semantically coherent text sections or “chunks.” ChunkRAG evaluates each chunk individually to determine its relevance to the user’s query, thereby avoiding irrelevant information that might dilute response accuracy. This precise filtering technique enhances the model’s ability to generate contextually accurate responses, a significant improvement over broader document-level filtering methods.
ChunkRAG’s methodology involves breaking down documents into manageable, semantically coherent chunks. This process includes several stages: documents are first segmented, and each chunk is scored for relevance using a multi-level LLM-driven evaluation system. This system incorporates a self-reflection mechanism and employs a secondary “critic” LLM that reviews initial relevance scores, ensuring a balanced and accurate assessment of each chunk. Unlike other RAG models, ChunkRAG adjusts its scoring dynamically, fine-tuning relevance thresholds based on the content. This comprehensive chunk-level filtering process reduces the risk of hallucinations and delivers more accurate, user-specific responses.
The effectiveness of ChunkRAG was tested on the PopQA benchmark, a dataset used to evaluate the accuracy of short-form question-answering models. In these tests, ChunkRAG achieved a notable accuracy score of 64.9%, a significant 10-point improvement over CRAG, the closest competing model with an accuracy of 54.9%. This improvement is particularly meaningful in knowledge-intensive tasks requiring high factual consistency. ChunkRAG’s performance gains extend beyond simple question answering; the model’s chunk-level filtering reduces irrelevant data by over 15% compared to traditional RAG systems, demonstrating its potential in fact-checking applications and other complex query tasks that demand stringent accuracy standards.
This research highlights a crucial advancement in the design of RAG systems, offering a solution to the common problem of irrelevant data in retrieved content. ChunkRAG can achieve better accuracy than existing models without sacrificing response relevance by implementing chunk-level filtering. Its focus on dynamically adjusting relevance thresholds and using multiple LLM assessments per chunk makes it a promising tool for applications where precision is paramount. Also, this method’s reliance on fine-grained filtering rather than generic document-level retrieval enhances its adaptability, making it highly effective across various knowledge-driven fields.

Key takeaways from the ChunkRAG include:
- Improved Accuracy: Achieved 64.9% accuracy on PopQA, surpassing traditional RAG systems by ten percentage points.
- Enhanced Filtering: Utilizes chunk-level filtering, reducing irrelevant information by approximately 15% compared to standard document-level methods.
- Dynamic Relevance Scoring: Introduces a self-reflection mechanism and “critic” scoring, resulting in more precise relevance assessments.
- Adaptable for Complex Tasks: It is especially suitable for applications like multi-hop reasoning and fact-checking, where precision in retrieval is essential.
- Potential for Broader Application: Designed with scalability in mind, ChunkRAG could extend to other datasets, such as Biography and PubHealth, to further demonstrate its effectiveness across different retrieval-intensive domains.

In conclusion, ChunkRAG offers an innovative solution to the limitations of traditional RAG models by focusing on chunk-level filtering and dynamic relevance scoring. This approach significantly improves generated responses’ accuracy and factual reliability, making ChunkRAG a valuable model for applications requiring precise information. By refining retrieval at the chunk level, this research demonstrates a path forward for RAG systems to meet better the needs of fact-checking, multi-hop reasoning, and other fields where the quality and relevance of information are critical.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
