Enhancing Text Retrieval: Overcoming the Limitations with Contextual Document Embeddings


Text retrieval in machine learning faces significant challenges in developing effective methods for indexing and retrieving documents. Traditional approaches relied on sparse lexical matching methods like BM25, which used n-gram frequencies. However, these statistical models have limitations in capturing semantic relationships and context. The primary neural method, a dual encoder architecture, encodes documents and queries into a dense latent space for retrieval. However, it needs to improve the ability to easily utilize previous corpus statistics such as inverse document frequency (IDF). This limitation makes neural models less adaptable to specific retrieval domains, as they need more context dependence than statistical models.
Researchers have made various attempts to address the challenges in text retrieval. Biencoder text embedding models like DPR, GTR, Contriever, LaPraDoR, Instructor, Nomic-Embed, E5, and GTE have been developed to improve retrieval performance. Some efforts have focused on adapting these models to new corpora at test time, proposing solutions such as unsupervised span-sampling, training on test corpora, and distillation from re-rankers. Moreover, other approaches include query clustering before training and considering contrastive batch sampling as a global optimization problem. Test-time adaptation techniques like pseudo-relevance feedback have also been explored, where relevant documents are used to enhance query representation.
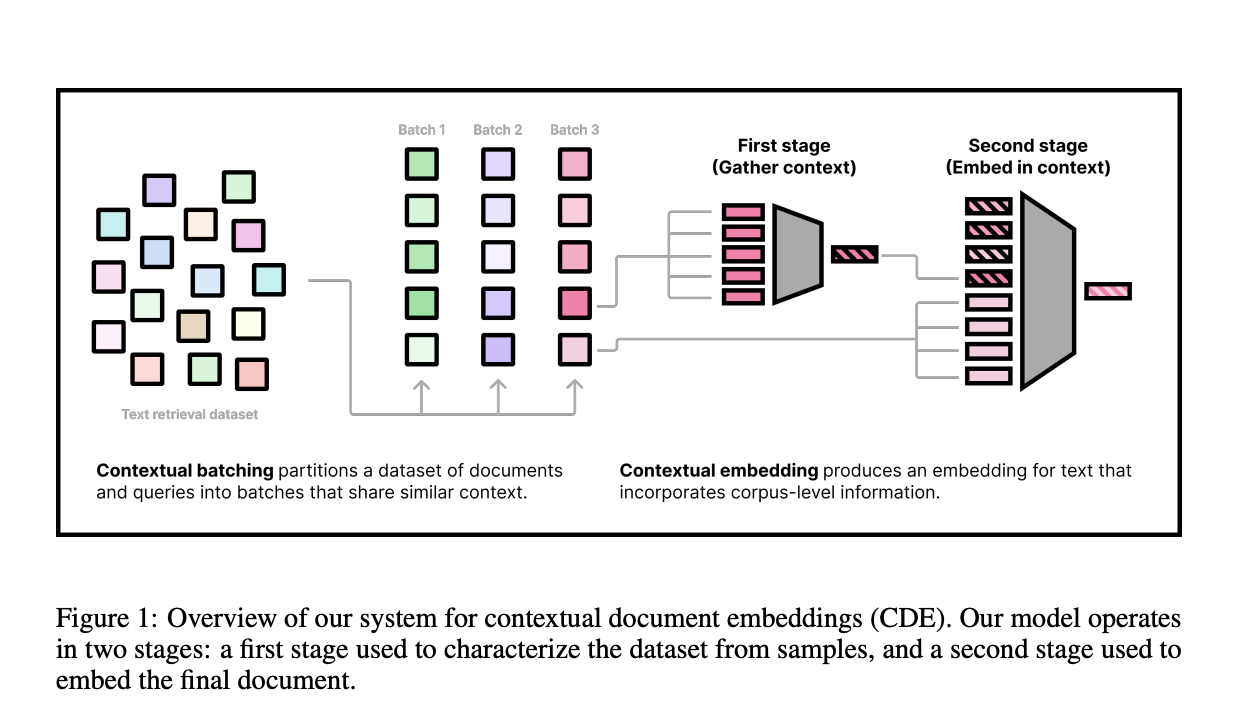
Researchers from Cornell University have proposed an approach to address the limitations of current text retrieval models. Researchers argue that existing document embeddings lack context for targeted retrieval use cases and suggest that document embeddings should consider both the document itself and its neighboring documents. Two complementary methods are developed to achieve this, for creating contextualized document embeddings. The first method introduces an alternative contrastive learning objective that explicitly adds document neighbors into the intra-batch contextual loss. The second method presents a new contextual architecture that directly encodes neighboring document information into the representation.
The proposed method utilizes a two-phase training approach: a large weakly-supervised pre-training phase and a short supervised phase. The initial setup to conduct experiments uses a small setting with a six-layer transformer, a maximum sequence length of 64, and up to 64 additional contextual tokens. This is evaluated on a truncated version of the BEIR benchmark, with various batch and cluster sizes. For the large setting, a single model is trained on sequences of length 512 with 512 contextual documents and evaluated on the full MTEB benchmark. The training data included 200M weakly supervised data points from internet sources and 1.8M human-written query-document pairs from retrieval datasets. The model uses NomicBERT as its backbone, with 137M parameters.
The contextual batching approach demonstrated a strong correlation between batch difficulty and downstream performance, where harder batches in contrastive learning lead to better gradient approximation and more effective learning. The contextual architecture has improved performance across all downstream datasets, with improvements in smaller, out-of-domain datasets like ArguAna and SciFact. The model gains optimal performance when trained on a full scale after four epochs on the BGE meta-datasets. The model “cde-small-v1” obtained state-of-the-art results on the MTEB benchmark compared to same-size models, showing enhanced embedding performance across multiple domains like clustering, classification, and semantic similarity.
In this paper, researchers from Cornell University have proposed a method to address the limitations of current text retrieval models. This paper consists of two significant improvements to traditional “biencoder” models for generating embeddings. The first enhancement introduces an algorithm for reordering training data points to create more challenging batches, which enhances vanilla training with minimal modifications. The second improvement introduces a corpus-aware architecture for retrieval, enabling the training of a state-of-the-art text embedding model. This contextual architecture effectively incorporates neighboring document information, addressing the limitations of context-independent embeddings.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.
