Block Transformer: Enhancing Inference Efficiency in Large Language Models Through Hierarchical Global-to-Local Modeling


Large language models (LLMs) have gained widespread popularity, but their token generation process is computationally expensive due to the self-attention mechanism. This mechanism requires attending to all previous tokens, leading to substantial computational costs. Although caching key-value (KV) states across layers during autoregressive decoding is now a common approach, it still involves loading the KV states of all prior tokens to calculate self-attention scores. This KV cache IO dominates the inference cost for LLMs. Despite various techniques proposed to reduce attention component costs, developing transformer-based LM architectures that avoid attention overhead remains a significant challenge.
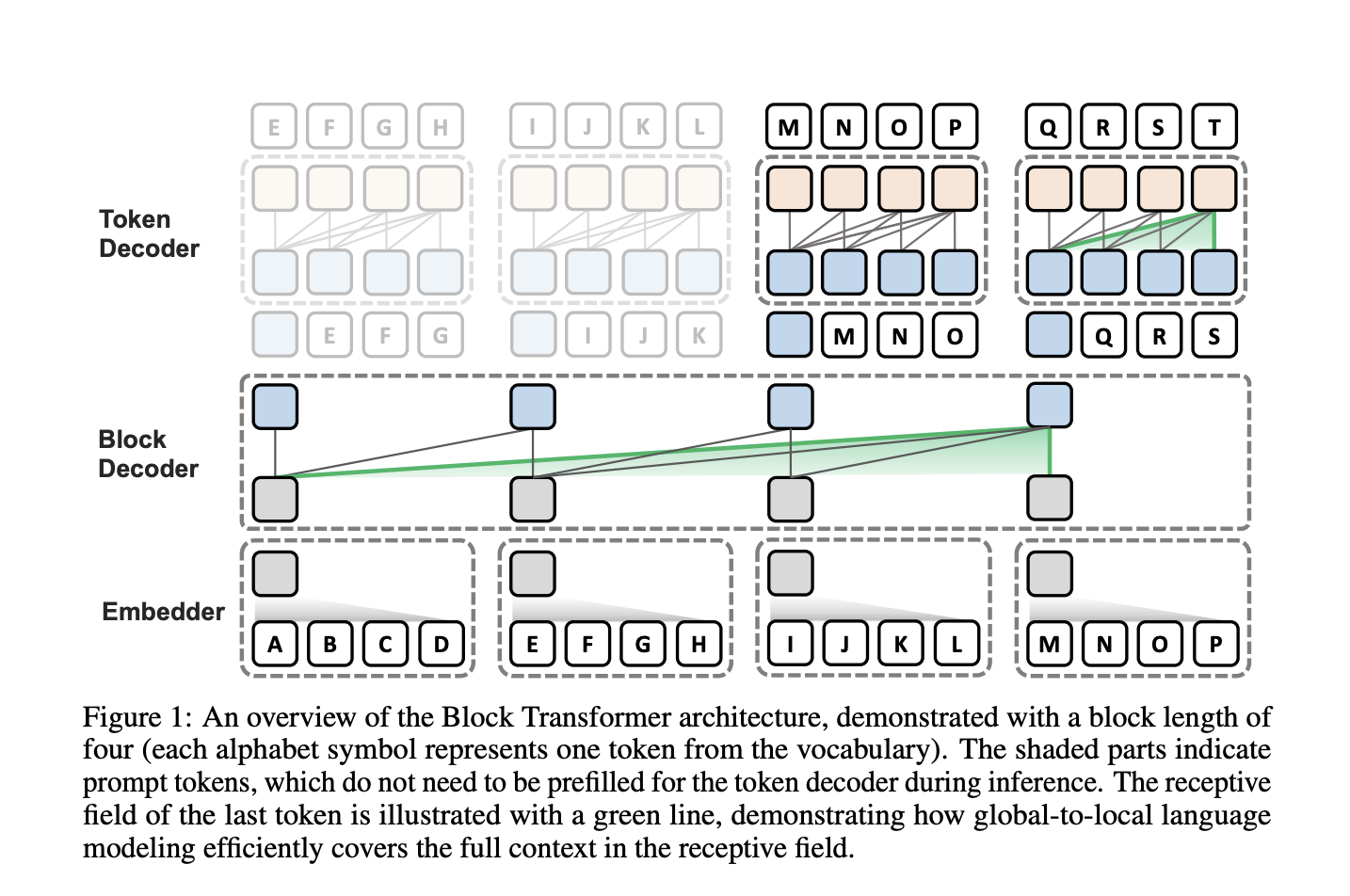
Researchers from KAIST AI, LG AI Research, and Google DeepMind have proposed Block Transformer architecture to address the inference bottlenecks of self-attention in autoregressive transformers. This approach adopts hierarchical global-to-local modeling to mitigate the significant KV cache IO bottleneck in batch inference. The Block Transformer separates the costly global modeling into the lower layers while using faster local modeling in the upper layers. The architecture then aggregates input tokens into fixed-size blocks and applies self-attention at this coarse level to reduce costs in lower layers. Moreover, it shows 10-20x gains in inference throughput compared to vanilla transformers with similar perplexity, marking a new approach for optimizing language model inference through global-to-local modeling.
The Block Transformer architecture consists of two distinct stages: global context comprehension and detailed local interactions. Lower layers capture global context at a coarse block-level granularity, and upper layers resolve local dependencies. Moreover, the coarse-grained global modeling reduces the KV cache bottlenecks, while local decoding nearly eliminates KV cache overhead and prefill costs. It allows the token decoder to utilize more FLOPs for fine-grained language modeling with minimal impact on inference throughput. The architecture’s efficiency gains are evident in both prefill and decode stages, addressing key bottlenecks in traditional transformer models.
The Block Transformer demonstrates comparable language modeling performance to vanilla models with equivalent parameters, achieving similar perplexity and accuracy on zero-shot evaluation tasks. It shows an increase of 25 times in throughput under both prefill-heavy and decode-heavy scenarios. This improvement comes from significant reductions in KV cache memory, enabling batch sizes that are six times larger. The architecture also reduces latency in prefill-heavy situations. Moreover, the Block Transformer maintains high throughput with longer prompt lengths, outperforming vanilla models with shorter prompts. It enhances throughput even further in scenarios with contexts exceeding one million tokens.
Researchers further compared the proposed transformer with the MEGABYTE model, showing a throughput increase of over 1.5 times compared to MEGABYTE. This improvement is attributed to enhanced local computational capacity. Moreover, the global-to-local modeling approach aligns with recent studies on KV cache compression algorithms that preserve only meaningful tokens based on accumulated attention scores. The Block Transformer exhibits a similar attention pattern, with most attention sinking into the first token. This observation suggests a potential for further performance enhancement using global embeddings or context embeddings from the previous window.
In conclusion, researchers introduced Block Transformer architecture to address the inference bottlenecks of self-attention in autoregressive transformers. It provides an approach to autoregressive transformers by leveraging global-to-local modeling, demonstrating significant inference-time advantages. The paper highlights the crucial roles of global and local components in language modeling, working on the previously overlooked inference benefits of the token decoder. The Block Transformer achieves substantial throughput improvements compared to vanilla transformers of equivalent performance with the help of strategic architectural design. The broader impacts of this design underscore its potential to influence various applications of language models across different domains.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Want to get in front of 1 Million+ AI Readers? Work with us here

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.
