DreamHOI: A Novel AI Approach for Realistic 3D Human-Object Interaction Generation Using Textual Descriptions and Diffusion Models


Early attempts in 3D generation focused on single-view reconstruction using category-specific models. Recent advancements utilize pre-trained image and video generators, particularly diffusion models, to enable open-domain generation. Fine-tuning on multi-view datasets improved results, but challenges persisted in generating complex compositions and interactions. Efforts to enhance compositionality in image generative models faced difficulties in transferring techniques to 3D generation. Some methods extended distillation approaches to compositional 3D generation, optimizing individual objects and spatial relationships while adhering to physical constraints.
Human-object interaction synthesis has progressed with methods like InterFusion, which generates interactions based on textual prompts. However, limitations in controlling human and object identities persist. Many approaches struggle to preserve human mesh identity and structure during interaction generation. These challenges highlight the need for more effective techniques that allow greater user control and practical integration into virtual environment production pipelines. This paper builds upon previous efforts to address these limitations and enhance the generation of human-object interactions in 3D environments.
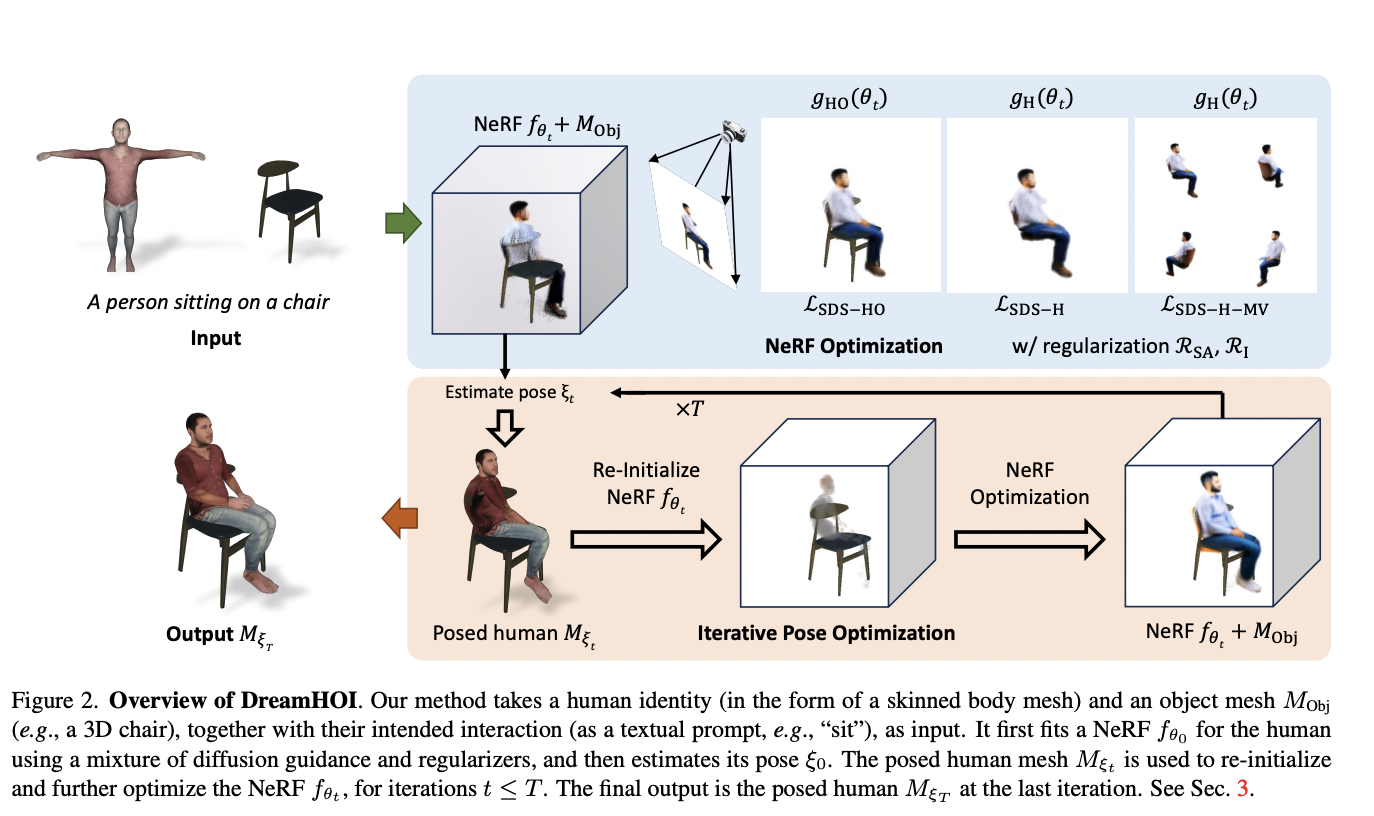
Researchers from the University of Oxford and Carnegie Mellon University introduced a zero-shot method for synthesizing 3D human-object interactions using textual descriptions. The approach leverages text-to-image diffusion models to address challenges arising from diverse object geometries and limited datasets. It optimizes human mesh articulation using Score Distillation Sampling gradients from these models. The method employs a dual implicit-explicit representation, combining neural radiance fields with skeleton-driven mesh articulation to preserve character identity. This innovative approach bypasses extensive data collection, enabling realistic HOI generation for a wide range of objects and interactions, thereby advancing the field of 3D interaction synthesis.
DreamHOI employs a dual implicit-explicit representation, combining neural radiance fields (NeRFs) with skeleton-driven mesh articulation. This approach optimizes skinned human mesh articulation while preserving character identity. The method utilizes Score Distillation Sampling to obtain gradients from pre-trained text-to-image diffusion models, guiding the optimization process. The optimization alternates between implicit and explicit forms, refining mesh articulation parameters to align with textual descriptions. Rendering the skinned mesh alongside the object mesh allows for direct optimization of explicit pose parameters, enhancing efficiency due to the reduced number of parameters.
Extensive experimentation validates DreamHOI’s effectiveness. Ablation studies assess the impact of various components, including regularizers and rendering techniques. Qualitative and quantitative evaluations demonstrate the model’s performance compared to baselines. Diverse prompt testing showcases the method’s versatility in generating high-quality interactions across different scenarios. The implementation of a guidance mixture technique further enhances optimization coherence. This comprehensive methodology and rigorous testing establish DreamHOI as a robust approach for generating realistic and contextually appropriate human-object interactions in 3D environments.
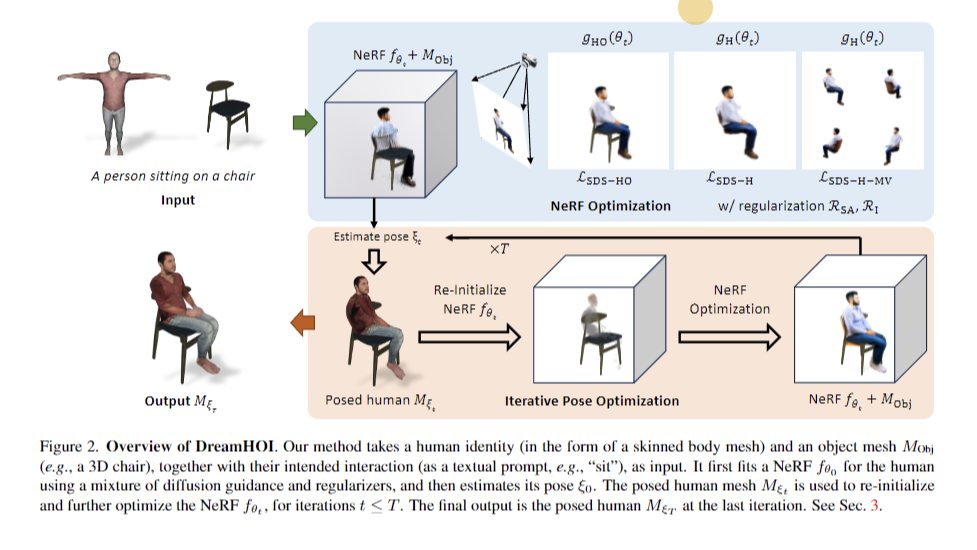
DreamHOI excels in generating 3D human-object interactions from textual prompts, outperforming baselines with higher CLIP similarity scores. Its dual implicit-explicit representation combines NeRFs and skeleton-driven mesh articulation, enabling flexible pose optimization while preserving character identity. The two-stage optimization process, including 5000 steps of NeRF refinement, contributes to high-quality results. Regularizers play a crucial role in maintaining proper model size and alignment. A regressor facilitates transitions between NeRF and skinned mesh representations. DreamHOI overcomes the limitations of methods like DreamFusion in maintaining mesh identity and structure. This approach shows promise for applications in film and game production, simplifying the creation of realistic virtual environments with interacting humans.
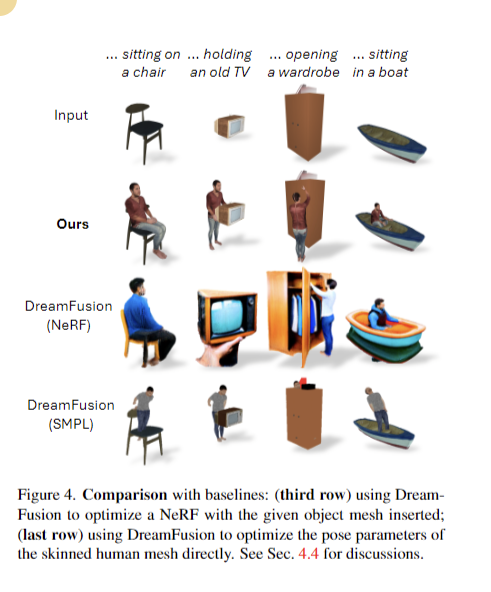
In conclusion, DreamHOI introduces a novel approach for generating realistic 3D human-object interactions using textual prompts. The method employs a dual implicit-explicit representation, combining NeRFs with explicit pose parameters of skinned meshes. This approach, along with Score Distillation Sampling, optimizes pose parameters effectively. Experimental results demonstrate DreamHOI’s superior performance compared to baseline methods, with ablation studies confirming the importance of each component. The paper addresses challenges in direct optimization of pose parameters and highlights DreamHOI’s potential to simplify virtual environment creation. This advancement opens up new possibilities for applications in the entertainment industry and beyond.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
⏩ ⏩ FREE AI WEBINAR: ‘SAM 2 for Video: How to Fine-tune On Your Data’ (Wed, Sep 25, 4:00 AM – 4:45 AM EST)

Shoaib Nazir is a consulting intern at MarktechPost and has completed his M.Tech dual degree from the Indian Institute of Technology (IIT), Kharagpur. With a strong passion for Data Science, he is particularly interested in the diverse applications of artificial intelligence across various domains. Shoaib is driven by a desire to explore the latest technological advancements and their practical implications in everyday life. His enthusiasm for innovation and real-world problem-solving fuels his continuous learning and contribution to the field of AI
