MINT-1T Dataset Released: A Multimodal Dataset with One Trillion Tokens to Build Large Multimodal Models


Artificial intelligence, particularly in training large multimodal models (LMMs), relies heavily on vast datasets that include sequences of images and text. These datasets enable the development of sophisticated models capable of understanding and generating multimodal content. As AI models’ capabilities advance, the need for extensive, high-quality datasets becomes even more critical, driving researchers to explore new data collection and curation methods.
A significant challenge in AI research is the need for large-scale, open-source, multimodal interleaved datasets. These datasets are essential for training models seamlessly integrating text and image data. The limited availability of such datasets hampers the development of robust and high-performing open-source models, resulting in a performance gap between open-source and proprietary models. Addressing this gap requires innovative approaches to dataset creation that can provide the necessary scale and diversity.
Existing methods for creating multimodal datasets often involve collecting and curating data from HTML documents. Notable datasets like OBELICS have been instrumental but are limited in scale and diversity, primarily sourcing data from HTML. This restriction affects the variety and richness of the data, impacting the performance and applicability of the resulting AI models. Researchers have found that datasets sourced solely from HTML documents must capture the full spectrum of required multimodal content for comprehensive model training.
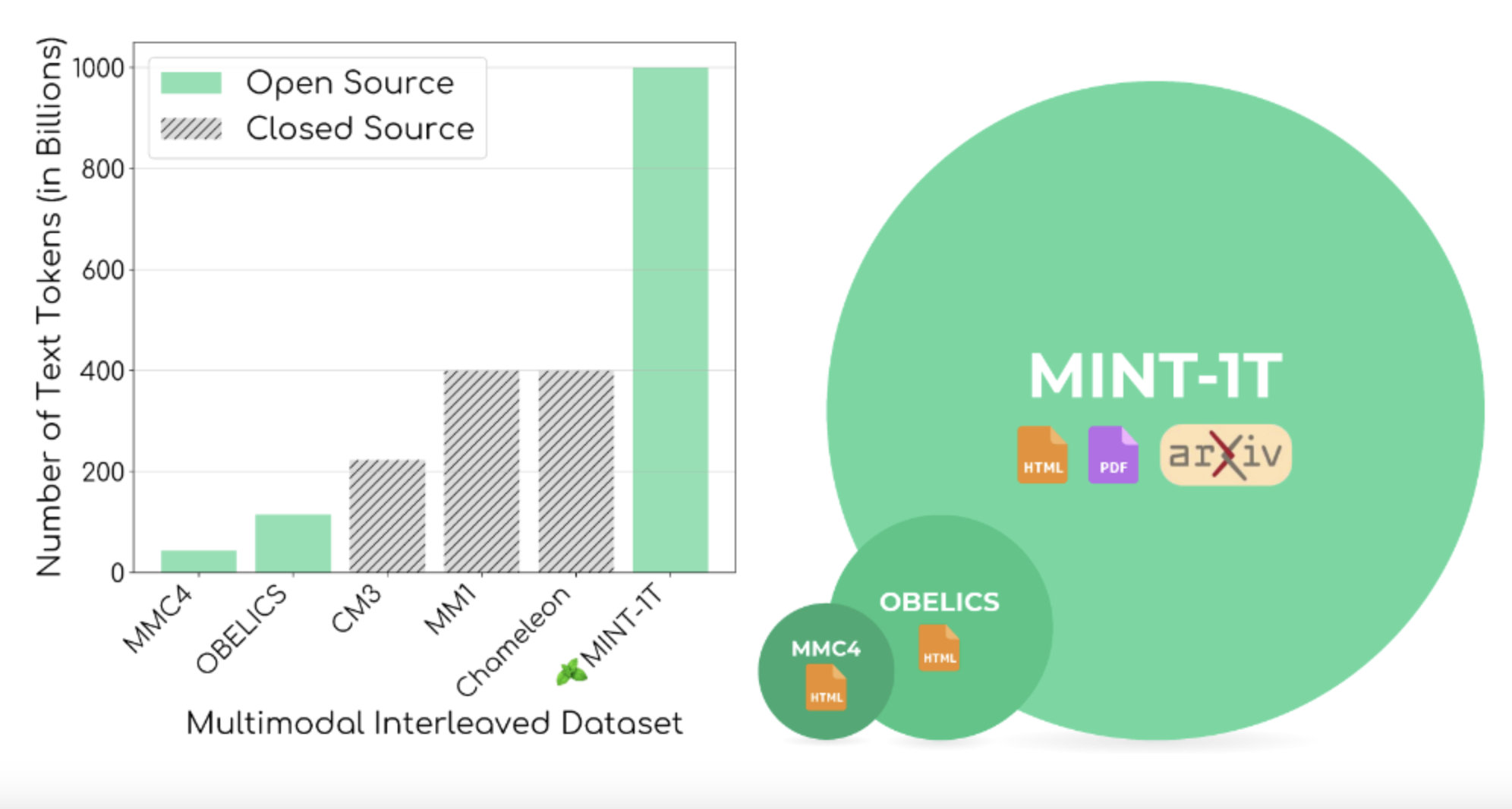
Researchers from the University of Washington, Salesforce Research, Stanford University, the University of Texas at Austin, and the University of California Berkeley introduced MINT-1T, the most extensive & diverse open-source multimodal interleaved dataset to date, addressing the need for larger and more varied datasets. MINT-1T comprises one trillion text tokens and 3.4 billion images from HTML, PDFs, and ArXiv papers. This dataset represents a tenfold increase from previous datasets, significantly enhancing the data for training multimodal models. Institutions such as the University of Washington and Salesforce Research collaborated on this initiative, demonstrating a concerted effort to bridge the gap in dataset availability.
Creating the MINT-1T dataset involved an intricate process of sourcing, filtering, and deduplicating data. HTML documents were expanded to include data from earlier years, and PDFs were processed to extract readable text and images. ArXiv papers were parsed for figures and text, ensuring a comprehensive collection of multimodal content. Advanced filtering methods were employed to remove low-quality, non-English, and inappropriate content. Deduplication processes were also implemented to eliminate repetitive data, ensuring the dataset’s quality and diversity.
Experiments demonstrated that LMMs trained on the MINT-1T dataset matched and often surpassed the performance of models trained on previous leading datasets like OBELICS. Including more diverse sources in MINT-1, T resulted in better generalization and performance across various benchmarks. Notably, the dataset significantly improved performance in tasks involving visual question answering and multimodal reasoning. The researchers found that models trained on MINT-1T performed better across multiple demonstrations, highlighting the dataset’s effectiveness.

The MINT-1T dataset’s construction included detailed steps to ensure data quality and diversity. For instance, the dataset consists of 922 billion HTML tokens, 106 billion PDF tokens, and 9 billion ArXiv tokens. The filtering process involved eliminating documents with inappropriate content and non-English texts, using tools like Fasttext for language identification and NSFW detectors for image content. The deduplication process was crucial, involving Bloom filters to remove duplicate paragraphs and documents and hashing techniques to eliminate repetitive images.

In conclusion, the MINT-1T dataset addresses dataset scarcity and diversity. By introducing a larger and more varied dataset, the researchers have enabled the development of more robust and high-performing open-source multimodal models. This work highlights the importance of data diversity and scale in AI research and paves the way for future improvements and applications in multimodal AI. The dataset’s extensive scale, including one trillion text tokens and 3.4 billion images, provides a solid foundation for advancing AI capabilities.
Check out the Paper, Details, and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.

